Pandas
1. Khởi tạo dataframe
Đây là cách thường ít được áp dụng vì khi làm việc chúng ta thường đọc dữ liệu từ những file dữ liệu có sẵn được lưu dưới dạng csv hoặc txt. Nhưng đôi khi chúng ta cũng cần khởi tạo dataframe từ đầu chẳng hạn như bạn muốn lưu kết quả log file của chương trình vào một dataframe và save dưới dạng csv sau đó. Việc lưu trữ dưới dạng dataframe sẽ giúp cho bạn dễ dàng thực hiện các phép lọc, thống kê và visualize trực tiếp từ dataframe một cách dễ dàng hơn.
Đưới đây mình sẽ giới thiệu hai cách khởi tạo dataframe chính trực tiếp từ câu lệnh pd.DataFrame(.).
1.1. Khởi tạo thông qua dictionary
from IPython.display import display
pd.set_option('max_colwidth', 40)
pd.set_option('precision', 5)
pd.set_option('max_rows', 10)
pd.set_option('max_columns', 30)
'contents':['Author', 'Book', 'Target', 'No_Donation'],
'infos':['Pham Dinh Khanh', 'ML algorithms to Practice', 'Vi mot cong dong AI vung manh hon', 'Community'],
'numbers':[1993, 2021, 1, 2]
}
display(df)
| contents | infos | numbers | |
|---|---|---|---|
| 0 | Author | Pham Dinh Khanh | 1993 |
| 1 | Book | ML algorithms to Practice | 2021 |
| 2 | Target | Vi mot cong dong AI vung manh hon | 1 |
| 3 | No_Donation | Community | 2 |
Hàm display của IPython giúp cho DataFrame hiển thị được trên code khi run dưới dạng script file. các options của pd.set_option() lần lượt có tác dụng:
-
max_colwidth: Qui định chiều rộng tối đa của một cột. -
precision: Độ chính xác của các sau dấu phảy của các cột định dạng float. -
max_columns,max_rows: Lần lượt là độ số lượng cột và số lượng dòng tối đa được hiển thị.
Tiếp theo chúng ta sẽ khởi tạo thông qua list các dòng.
1.2. Khởi tạo thông qua list các dòng
Theo cách này chúng ta sẽ truyền vào data là một list gồm các tupple mà mỗi tupple là một dòng dữ liệu. đối số columns sẽ qui định tên cột theo đúng thứ tự được qui định ở mỗi dòng.
('Book', 'ML algorithms to Practice', 2021),
('Target', 'Vi mot cong dong AI vung manh hon', 1),
('No_Donation', 'Community', 2)]
df = pd.DataFrame(data = records, columns = ['contents', 'infos', 'numbers'])
df
| contents | infos | numbers | |
|---|---|---|---|
| 0 | Author | Pham Dinh Khanh | 1993 |
| 1 | Book | ML algorithms to Practice | 2021 |
| 2 | Target | Vi mot cong dong AI vung manh hon | 1 |
| 3 | No_Donation | Community | 2 |
Để lưu trữ một dataframe dưới dạng một file csv chúng ta dùng hàm .to_csv(.) tham số truyền vào là đường link save file. Chẳng hạn bên dưới ta lưu dataframe vào một file “data.csv” cùng thư mục với file notebook.
1.3. Đọc dữ liệu từ file
Chúng ta cũng có thể khởi tạo bảng bằng cách đọc file csv, txt, xls, xlsx, dat thông qua hàm pd.read_csv(.). Hàm này không chỉ đọc được những file có trên máy tính của bạn mà còn có thể download những file có trên mạng. Bên dưới chúng ta thực hành đọc dữ liệu về giá nhà ở tại Boston từ bộ dữ liệu BostonHousing. Bộ dữ liệu này gồm các trường:
-
crim: Tỷ lệ phạm tội phạm bình quân đầu người theo thị trấn.
-
zn: Tỷ lệ đất ở được quy hoạch cho các lô trên 25.000 foot square.
-
indus: Tỷ lệ diện tích thuộc lĩnh vực kinh doanh phi bán lẻ trên mỗi thị trấn.
-
chas: Biến giả, = 1 nếu được bao bởi sông Charles River, = 0 nếu ngược lại.
-
nox: Nồng độ khí Ni-tơ oxit.
-
rm: Trung bình số phòng trên một căn hộ.
-
age: Tỷ lệ căn hộ được xây dựng trước năm 1940.
-
dis: Khoảng cách trung bình có trọng số tới 5 trung tâm việc làm lớn nhất ở Boston.
-
rad: Chỉ số về khả năng tiếp cận đường cao tốc.
-
tax: Giá trị thuế suất tính trên đơn vị
10000$. -
ptratio: Tỷ lệ học sinh-giáo viên trên mỗi thị trấn.
-
black: Tỷ lệ số người da đen trong thị trấn được tính theo công thức: 1000(Bk−0.63)2 ở đây Bk là tỷ lệ người da đen trong thị trấn.
-
lstat: Tỷ lệ phần trăm dân số thu nhập thấp.
-
medv: median giá trị của nhà có người sở hữu tính trên đơn vị
1000$.
df.head()
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | b | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222 | 18.7 | 396.90 | 5.33 | 36.2 |
Trong hàm pd.read_csv() chúng ta sẽ khai báo các thông số chính bao gồm :
-
sep: Là viết tắt của seperator, ký hiệu ngăn cách các trường trong cùng một dòng, thường và mặc định là dấu phảy.
-
header: Mặc định là indice của dòng được chọn làm column name. Thường là dòng đầu tiên của file. Trường hợp file không có header thì để
header = None. Khi đó indices cho column name sẽ được mặc định là các số tự nhiên liên tiếp từ 0 cho đến indice column cuối cùng. -
index_col: Là indice của column được sử dụng làm giá trị index cho dataframe. cột index phải có giá trị khác nhau để phân biệt giữa các dòng và khi chúng ta để index_col = None thì giá trị index sẽ được đánh mặc định từ 0 cho đến dòng cuối cùng.
Hàm df.head() mặc định sẽ hiển thị ra 5 quan sát đầu tiên của dataframe. Chúng ta muốn hiển thị 5 quan sát cuối cùng thì dùng hàm df.tail() và 5 quan sát ngẫu nhiên thì dùng hàm df.sample(5).
Hàm df.info() sẽ cho ta biết định dạng và số lượng quan sát not-null của mỗi trường trong dataframe.
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 crim 506 non-null float64
1 zn 506 non-null float64
2 indus 506 non-null float64
3 chas 506 non-null int64
4 nox 506 non-null float64
5 rm 506 non-null float64
6 age 506 non-null float64
7 dis 506 non-null float64
8 rad 506 non-null int64
9 tax 506 non-null int64
10 ptratio 506 non-null float64
11 b 506 non-null float64
12 lstat 506 non-null float64
13 medv 506 non-null float64
dtypes: float64(11), int64(3)
memory usage: 55.5 KB
Hoặc chúng ta có thể dùng hàm df.dtypes để kiểm tra định dạng dữ liệu các trường của một bảng.
df.dtypes
zn float64
indus float64
chas int64
nox float64
...
tax int64
ptratio float64
b float64
lstat float64
medv float64
Length: 14, dtype: object
Nếu muốn kiểm tra chi tiết hơn những thống kê mô tả của dataframe như trung bình, phương sai, min, max, median của một trường dữ liệu chúng ta dùng hàm df.describe()
df.describe()
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | b | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 | 506.00000 |
| mean | 3.61352 | 11.36364 | 11.13678 | 0.06917 | 0.55470 | 6.28463 | 68.57490 | 3.79504 | 9.54941 | 408.23715 | 18.45553 | 356.67403 | 12.65306 | 22.53281 |
| std | 8.60155 | 23.32245 | 6.86035 | 0.25399 | 0.11588 | 0.70262 | 28.14886 | 2.10571 | 8.70726 | 168.53712 | 2.16495 | 91.29486 | 7.14106 | 9.19710 |
| min | 0.00632 | 0.00000 | 0.46000 | 0.00000 | 0.38500 | 3.56100 | 2.90000 | 1.12960 | 1.00000 | 187.00000 | 12.60000 | 0.32000 | 1.73000 | 5.00000 |
| 25% | 0.08204 | 0.00000 | 5.19000 | 0.00000 | 0.44900 | 5.88550 | 45.02500 | 2.10018 | 4.00000 | 279.00000 | 17.40000 | 375.37750 | 6.95000 | 17.02500 |
| 50% | 0.25651 | 0.00000 | 9.69000 | 0.00000 | 0.53800 | 6.20850 | 77.50000 | 3.20745 | 5.00000 | 330.00000 | 19.05000 | 391.44000 | 11.36000 | 21.20000 |
| 75% | 3.67708 | 12.50000 | 18.10000 | 0.00000 | 0.62400 | 6.62350 | 94.07500 | 5.18843 | 24.00000 | 666.00000 | 20.20000 | 396.22500 | 16.95500 | 25.00000 |
| max | 88.97620 | 100.00000 | 27.74000 | 1.00000 | 0.87100 | 8.78000 | 100.00000 | 12.12650 | 24.00000 | 711.00000 | 22.00000 | 400.00000 | 20.00000 | 50.00000 |
1.4. Export to CSV, EXCEL, TXT, JSON
Đây là câu lệnh được sử dụng khá phổ biến để lưu trữ các file dữ liệu từ dataframe sang những định dạng khác nhau. Những định dạng này sẽ cho phép chúng ta load lại dữ liệu bằng các hàm read_csv(), read_xlsx(), read_txt(), read_json() sau đó.
df.to_csv('BostonHousing.csv', index = False)
# Lưu file excel
df.to_excel('BostonHousing.xls', index = False)
# Lưu dữ file json
df.to_json('BostonHousing.json') #do not include index = False, index only use for table orient
2. Thao tác với dataframe
2.1. Truy cập dataframe
Chúng ta có thể truy cập dataframe theo hai cách.
Truy cập theo slice index: Theo cách này chúng ta chỉ cần truyền vào index của dòng và cột và sử dụng hàm df.iloc[rows_slice, columns_slice] để trích xuất ra các dòng và cột tương ứng. Cách lấy slice cho rows và columns hoàn toàn tương tự như truy cập slice index trong list.
Note: iloc là viết tắt của indice location, tức là truy cập quan indice.
df.iloc[:5, :5]
| crim | zn | indus | chas | nox | |
|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 |
| 3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 |
| 4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 |
df.iloc[5:10, 2:4]
| indus | chas | |
|---|---|---|
| 5 | 2.18 | 0 |
| 6 | 7.87 | 0 |
| 7 | 7.87 | 0 |
| 8 | 7.87 | 0 |
| 9 | 7.87 | 0 |
df.iloc[-5:, [1, 3]]
| zn | chas | |
|---|---|---|
| 501 | 0.0 | 0 |
| 502 | 0.0 | 0 |
| 503 | 0.0 | 0 |
| 504 | 0.0 | 0 |
| 505 | 0.0 | 0 |
Ngoài ra ta cũng có thể truy cập các dòng theo row index của dataframe thông qua câu lệnh df.loc[].
df.loc[10:15]
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | b | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 0.22489 | 12.5 | 7.87 | 0 | 0.524 | 6.377 | 94.3 | 6.3467 | 5 | 311 | 15.2 | 392.52 | 20.45 | 15.0 |
| 11 | 0.11747 | 12.5 | 7.87 | 0 | 0.524 | 6.009 | 82.9 | 6.2267 | 5 | 311 | 15.2 | 396.90 | 13.27 | 18.9 |
| 12 | 0.09378 | 12.5 | 7.87 | 0 | 0.524 | 5.889 | 39.0 | 5.4509 | 5 | 311 | 15.2 | 390.50 | 15.71 | 21.7 |
| 13 | 0.62976 | 0.0 | 8.14 | 0 | 0.538 | 5.949 | 61.8 | 4.7075 | 4 | 307 | 21.0 | 396.90 | 8.26 | 20.4 |
| 14 | 0.63796 | 0.0 | 8.14 | 0 | 0.538 | 6.096 | 84.5 | 4.4619 | 4 | 307 | 21.0 | 380.02 | 10.26 | 18.2 |
| 15 | 0.62739 | 0.0 | 8.14 | 0 | 0.538 | 5.834 | 56.5 | 4.4986 | 4 | 307 | 21.0 | 395.62 | 8.47 | 19.9 |
Truy cập theo column names: Đây là cách được sử dụng phổ biến vì nó tường minh hơn. Theo cách này chúng ta sẽ truy cập các trường của dataframe bằng cách khai báo list column_names của chúng.
Ví dụ bên dưới chúng ta cần lấy ra các trường ['crim', 'tax', 'rad'] từ bảng df. Ta sẽ làm như sau:
| crim | tax | rad | |
|---|---|---|---|
| 0 | 0.00632 | 296 | 1 |
| 1 | 0.02731 | 242 | 2 |
| 2 | 0.02729 | 242 | 2 |
| 3 | 0.03237 | 222 | 3 |
| 4 | 0.06905 | 222 | 3 |
Kết hợp cả hai cách: Chúng ta có thể truy cập dataframe bằng cách kết hợp cả hai cách theo hướng sử dụng column names đối với cột và slice index đối với dòng:
df[['crim', 'tax', 'rad']].iloc[10:15]
| crim | tax | rad | |
|---|---|---|---|
| 10 | 0.22489 | 311 | 5 |
| 11 | 0.11747 | 311 | 5 |
| 12 | 0.09378 | 311 | 5 |
| 13 | 0.62976 | 307 | 4 |
| 14 | 0.63796 | 307 | 4 |
2.2. Lọc dataframe
Chúng ta có thể lọc dataframe thông qua các điều kiện đối với các trường. Điều kiện của trường được thể hiện như một biểu thức logic và bao trong dấu []. Giả sử chúng ta muốn lọc ra các thị trấn mà có số phòng ở trung bình trên căn hộ là trên 4 thì truyền vào dấu [] điều kiện df['rm'] > 4.
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | b | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222 | 18.7 | 396.90 | 5.33 | 36.2 |
Nếu chúng ta muốn kết hợp nhiều điều kiện thì dùng biểu thức logic and hoặc or. Ví dụ: Muốn lọc thêm điều kiện thuế suất trên 250 ngoài điều kiện số phòng thì ta làm như sau:
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | b | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296 | 15.3 | 396.90 | 4.98 | 24.0 |
| 6 | 0.08829 | 12.5 | 7.87 | 0 | 0.524 | 6.012 | 66.6 | 5.5605 | 5 | 311 | 15.2 | 395.60 | 12.43 | 22.9 |
| 7 | 0.14455 | 12.5 | 7.87 | 0 | 0.524 | 6.172 | 96.1 | 5.9505 | 5 | 311 | 15.2 | 396.90 | 19.15 | 27.1 |
| 8 | 0.21124 | 12.5 | 7.87 | 0 | 0.524 | 5.631 | 100.0 | 6.0821 | 5 | 311 | 15.2 | 386.63 | 29.93 | 16.5 |
| 9 | 0.17004 | 12.5 | 7.87 | 0 | 0.524 | 6.004 | 85.9 | 6.5921 | 5 | 311 | 15.2 | 386.71 | 17.10 | 18.9 |
Muốn lọc các cột theo định dạng dữ liệu thì như thế nào?
Ta dùng hàm df.select_dtypes() để lọc các cột theo định dạng dữ liệu. Những định dạng chính bao gồm integer, float, object, boolean. Ví dụ: Bên dưới chúng ta lọc các trường có định dạng dữ liệu là float.
| crim | zn | indus | nox | rm | age | dis | ptratio | b | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.538 | 6.575 | 65.2 | 4.0900 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.469 | 6.421 | 78.9 | 4.9671 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.469 | 7.185 | 61.1 | 4.9671 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.458 | 6.998 | 45.8 | 6.0622 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.458 | 7.147 | 54.2 | 6.0622 | 18.7 | 396.90 | 5.33 | 36.2 |
Lọc các cột theo pattern của tên cột
Khi làm việc với dữ liệu lớn sẽ có những tình huống mà bạn bắt gặp các cột thuộc về cùng một nhóm và chúng có chung một pattern. Chẳng hạn như về age sẽ có age_1, age_2, age_3,… Làm thế nào để bạn lọc ra được những biến này từ dữ liệu? Chúng ta sẽ dùng hàm filter. Đây là hàm cực kỳ tiện ích khi lọc cột từ những bộ dữ liệu lớn mà bạn sẽ thường xuyên sử dụng sau này.
'name':['a', 'b', 'c', 'd', 'e'],
'age_1':[1, 2, 3, 4, 5],
'age_2':[3, 5, 7, 9 , 10],
'age_3':[2, 5, 2, 5, 6]
})
| name | age_1 | age_2 | age_3 | |
|---|---|---|---|---|
| 0 | a | 1 | 3 | 2 |
| 1 | b | 2 | 5 | 5 |
| 2 | c | 3 | 7 | 2 |
| 3 | d | 4 | 9 | 5 |
| 4 | e | 5 | 10 | 6 |
Lựa chọn các cột bắt đầu là age thông qua hàm filter.
| age_1 | age_2 | age_3 | |
|---|---|---|---|
| 0 | 1 | 3 | 2 |
| 1 | 2 | 5 | 5 |
| 2 | 3 | 7 | 2 |
| 3 | 4 | 9 | 5 |
| 4 | 5 | 10 | 6 |
Trong pandas thì axis=1 là làm việc với cột và axis=0 là làm việc với dòng. Giá trị của regex=^age có nghĩa là lọc các cột có chuỗi ký tự là age đứng đầu.
2.3. Sort dữ liệu
Trong nhiều trường hợp bạn sẽ cần sort dữ liệu theo chiều từ thấp lên cao hoặc từ cao xuống thấp để biết đâu là những quan sát nhỏ nhất và lớn nhất cũng như việc tạo ra một đồ thị có trend rõ ràng và thể hiện quan hệ tuyến tính giữa các biến theo trend.
Để sort dữ liệu chúng ta sử dụng hàm df.sort_values(.). Lựa chọn là ascending = True giúp sort theo thứ tự tăng dần, trường hợp False sẽ giảm dần.
Giả sử bên dưới chúng ta cùng sort giá trị của căn nhà theo chiều giảm dần.
df.sort_values('medv', ascending = False).head()
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | b | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 283 | 0.01501 | 90.0 | 1.21 | 1 | 0.401 | 7.923 | 24.8 | 5.8850 | 1 | 198 | 13.6 | 395.52 | 3.16 | 50.0 |
| 225 | 0.52693 | 0.0 | 6.20 | 0 | 0.504 | 8.725 | 83.0 | 2.8944 | 8 | 307 | 17.4 | 382.00 | 4.63 | 50.0 |
| 369 | 5.66998 | 0.0 | 18.10 | 1 | 0.631 | 6.683 | 96.8 | 1.3567 | 24 | 666 | 20.2 | 375.33 | 3.73 | 50.0 |
| 370 | 6.53876 | 0.0 | 18.10 | 1 | 0.631 | 7.016 | 97.5 | 1.2024 | 24 | 666 | 20.2 | 392.05 | 2.96 | 50.0 |
| 371 | 9.23230 | 0.0 | 18.10 | 0 | 0.631 | 6.216 | 100.0 | 1.1691 | 24 | 666 | 20.2 | 366.15 | 9.53 | 50.0 |
chúng ta cũng có thể sort theo một nhóm các trường. Ví dụ để sort đồng thời giá trị của căn nhà và giá trị thuế suất thì ta truyền vào list các trường cần sort là ['medv', 'tax'].
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | b | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 368 | 4.89822 | 0.0 | 18.1 | 0 | 0.631 | 4.970 | 100.0 | 1.3325 | 24 | 666 | 20.2 | 375.52 | 3.26 | 50.0 |
| 369 | 5.66998 | 0.0 | 18.1 | 1 | 0.631 | 6.683 | 96.8 | 1.3567 | 24 | 666 | 20.2 | 375.33 | 3.73 | 50.0 |
| 370 | 6.53876 | 0.0 | 18.1 | 1 | 0.631 | 7.016 | 97.5 | 1.2024 | 24 | 666 | 20.2 | 392.05 | 2.96 | 50.0 |
| 371 | 9.23230 | 0.0 | 18.1 | 0 | 0.631 | 6.216 | 100.0 | 1.1691 | 24 | 666 | 20.2 | 366.15 | 9.53 | 50.0 |
| 372 | 8.26725 | 0.0 | 18.1 | 1 | 0.668 | 5.875 | 89.6 | 1.1296 | 24 | 666 | 20.2 | 347.88 | 8.88 | 50.0 |
2.4. Các hàm đối với một trường
2.4.1. Min, max, mean, meadian, sum
Trên một trường dữ liệu của dataframe đã tích hợp sẵn các hàm tính toán như min, max, mean, median, sum để tính các giá trị đặc trưng cho từng trường.
print(df['tax'].min(), df['tax'].max(), df['tax'].mean(), df['tax'].median(), df['tax'].sum())
2.4.2. Hàm cut
Hàm cut giúp ta phân chia giá trị của một trường liên tục vào những khoảng theo ngưỡng cắt. Kết quả trả ra là nhãn của từng khoảng mà chúng ta khai báo.
labels = ['low', 'normal', 'high']
# low: -999999 <- 250
# normal: 250 <- 400
# high: 400 <- 999999
df['tax_labels'] = pd.cut(df['tax'], bins=bins, labels=labels)
df[df['tax_labels']=='high'].head()
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | b | lstat | medv | tax_labels | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 54 | 0.01360 | 75.0 | 4.00 | 0 | 0.410 | 5.888 | 47.6 | 7.3197 | 3 | 469 | 21.1 | 396.90 | 14.80 | 18.9 | high |
| 111 | 0.10084 | 0.0 | 10.01 | 0 | 0.547 | 6.715 | 81.6 | 2.6775 | 6 | 432 | 17.8 | 395.59 | 10.16 | 22.8 | high |
| 112 | 0.12329 | 0.0 | 10.01 | 0 | 0.547 | 5.913 | 92.9 | 2.3534 | 6 | 432 | 17.8 | 394.95 | 16.21 | 18.8 | high |
| 113 | 0.22212 | 0.0 | 10.01 | 0 | 0.547 | 6.092 | 95.4 | 2.5480 | 6 | 432 | 17.8 | 396.90 | 17.09 | 18.7 | high |
| 114 | 0.14231 | 0.0 | 10.01 | 0 | 0.547 | 6.254 | 84.2 | 2.2565 | 6 | 432 | 17.8 | 388.74 | 10.45 | 18.5 | high |
2.4.3. Hàm qcut
Trong trường hợp chúng ta không muốn chia các bin dựa vào ngưỡng mà chỉ muốn khai báo số lượng bins và để cho hàm số tự quyết định ngưỡng để chia đều các quan sát vào các bins thì sử dụng hàm pd.qcut(.) (qcut là viết tắt của quantile cut). Bên dưới ta sẽ chia thành 3 bins (số bins sẽ được khai báo trong q=3) với labels tương ứng là ['low', 'normal', 'high']
labels = ['low', 'normal', 'high']
tax_labels = pd.qcut(df['tax'], q=3, labels=labels)
np.unique(tax_labels, return_counts = True)
Trường hợp muốn xác định tỷ lệ phần trăm luỹ kế của các ngưỡng phân chia ta có thể khai báo q là list gồm các ngưỡng luỹ kế. Ví dụ bên dưới ta muốn chia làm ba khoảng giá trị, mỗi khoảng chiếm 33% thì ta khai báo ngưỡng luỹ kế q = [0, 0.33, 0.66, 1]
2.4.4. Apply
Apply sẽ giúp ta biến đổi giá trị của một trường theo một hàm số xác định trước. Hàm số biến đổi được áp dụng trong apply sẽ là một hàm lamda. Hàm lambda là một khái niệm rất quan trọng trong python, hàm số này có cú pháp dạng lambda x: formula.
Phân tích kỹ hơn thì chúng ta thấy nó không có return. Điều này là phù hợp với ý nghĩa của hàm lambda vì nó không yêu cầu gía trị trả về ngay. Thực tế nó giống như một lời hứa sẽ thực hiện hàm đó tại thời điểm áp dụng một cách ngầm định bên trong một hàm khác (ở đây là hàm apply).
Ví dụ bên dưới ta muốn nhân đôi giá trị của tax thì có thể sử dụng hàm apply với lambda như sau:
1 484
2 484
3 444
4 444
Name: tax, dtype: int64
Ta cũng có thể áp dụng cho nhiều trường một lúc. Khi đó cần khai báo axis=1 để biết rằng ta đang áp dụng trên từng cột, nếu axis=0 thì sẽ áp dụng trên từng dòng.
| tax | medv | |
|---|---|---|
| 0 | 592.0 | 48.0 |
| 1 | 484.0 | 43.2 |
| 2 | 484.0 | 69.4 |
| 3 | 444.0 | 66.8 |
| 4 | 444.0 | 72.4 |
2.4.5. Map
Map là hàm giúp biến đổi giá trị của một biến sang giá trị mới dựa trên dictionary mà chúng ta áp dụng. Giá trị cũ sẽ là key và giá trị mới sẽ là value.
Bên dưới ta sẽ map các giá trị của trường df['tax_labels'] sang các giá trị tiếng Việt.
'low':'thap',
'normal':'tb',
'high':'cao'
}
1 thap
2 thap
3 thap
4 thap
Name: tax_labels, dtype: category
Categories (3, object): ['thap' < 'tb' < 'cao']
2.5. Biểu đồ matplotlib trên pandas
Chúng ta có thể nói rằng pandas rất mạnh vì nó đã wrap dường như toàn bộ các đồ thị cơ bản của matplotlib vào bên trong các hàm thành phần của pandas column. Do đó việc visualize trở nên vô cùng ngắn gọn, thậm chí là chỉ trên một dòng.
Bên dưới chúng ta sẽ cùng lướt qua nhanh các đồ thị cơ bản khi visualize trên pd.column. Biến được áp dụng đồng nhất cho các đồ thị là tax.
1. biểu đồ line
2. Biểu đồ line kết hợp với point
3. Biểu đồ barchart
Biều đồ này được dùng phù hợp khi chúng ta muốn so sánh chênh lệch giữa các nhóm về mặt giá trị tuyệt đối.
df_summary.plot.bar()
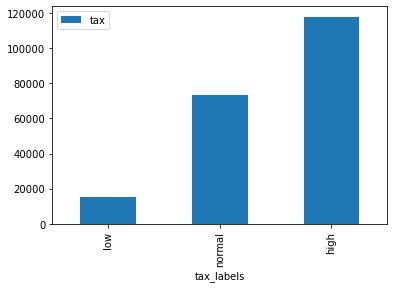
Ở đây ta sẽ phải dùng thêm hàm groupby để tạo thành bảng thống kê tổng thuế theo tax_labels rồi mới vẽ biểu đồ. Khi quen thuộc bạn có thể viết gọn hai câu lệnh lại thành một line như sau:
4. Biểu đồ pie
Đây là biểu đồ dùng để thể hiện giá trị phần trăm. Phù hợp khi so sánh giá trị tương đối giữa các nhóm.
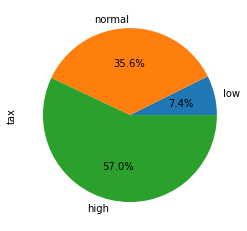
5. Biểu đồ boxplot
Biểu đồ boxplot sẽ được sử dụng để quan sát phân phối của biến đối với các giá trị min, max và các ngưỡng phân vị 25%, 50%, 75%. Căn cứ vào boxplot ta có thể biết được khoảng biến thiên của biến rộng hay hẹp, biến phân phối lệch trái hay phải.
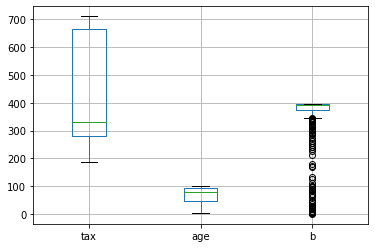
6. Biểu đồ area
Biểu đồ area cho ta biết diện tích nằm dưới đường biểu diễn và trên trục hoành.
